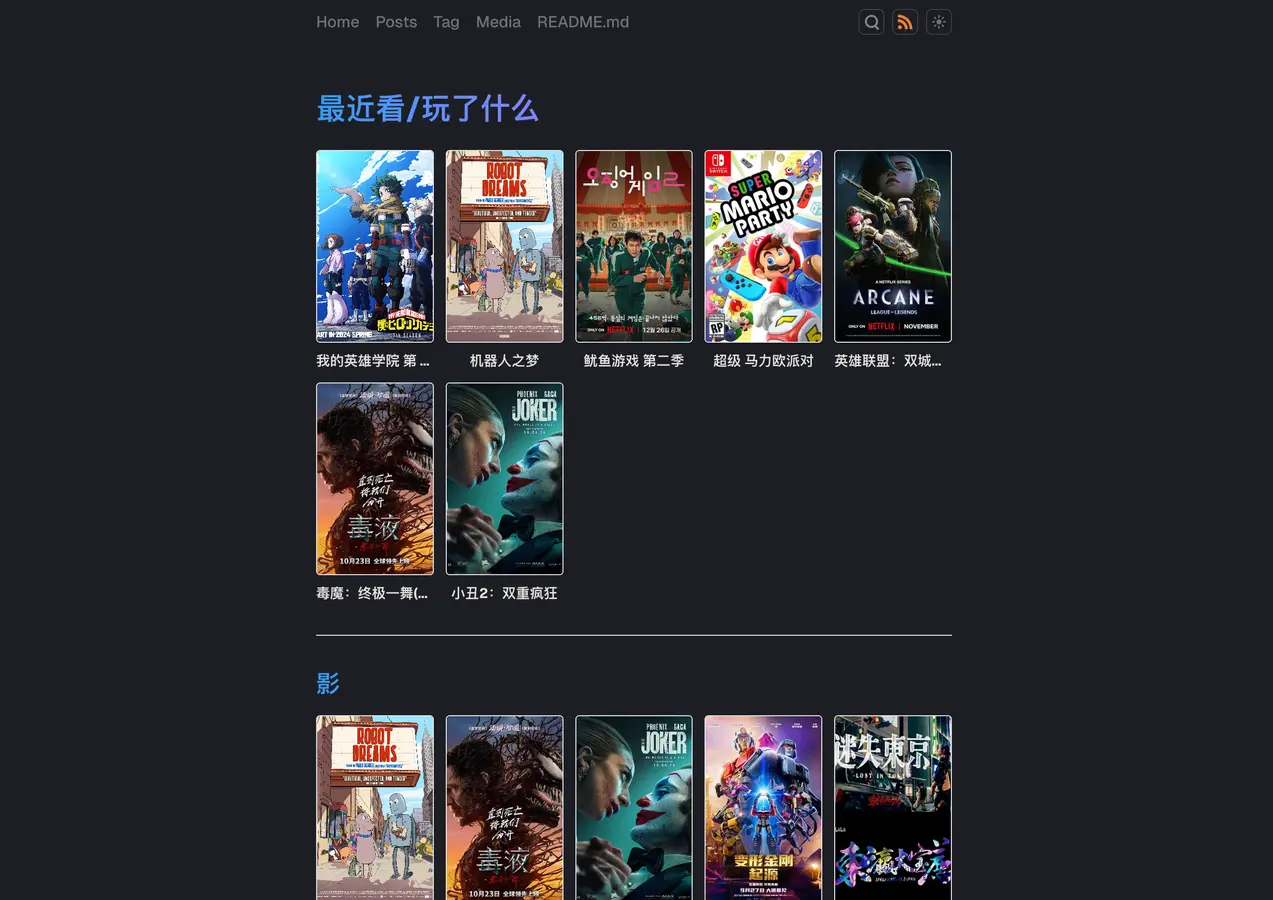
前言
曾几何时也是非常眼馋一些赛博友邻的观影页, 但是碍于没有相关的经验(懒)和Astro缺少相关的教程一直没有考虑过实现, 一开始的时候是想着这是一个动态服务, 所以可能需要考虑第三方服务来实现. 在看了几个博主是如何实现的后, 初步有了一些想法, 即可以用GitHub Action来实现. 因此, 本文所介绍的实现方式为:
- 使用GitHub Action调用NeoDB的API, 定期爬取并存储为json文件到库中.
- 使用Cloudflare加速并添加自定义域名.
- Astro读取json文件并渲染前端.
1.生成NeoDB API Token
如果我的描述不够清晰, 或许你可以从官方文档找到答案.
首先打开终端, 输入以下指令, client_name随意,redirect_uris可以填写为你的博客url再加上/callback, website为你的博客链接, 即前者去掉/callback:
curl https://neodb.social/api/v1/apps \ -d client_name=MyApp \ -d redirect_uris=https://blog.asyncx.top/callback \ -d website=https://blog.asyncx.top之后会返回如下格式的内容, 你需要留存client_id和client_secret供后文使用:
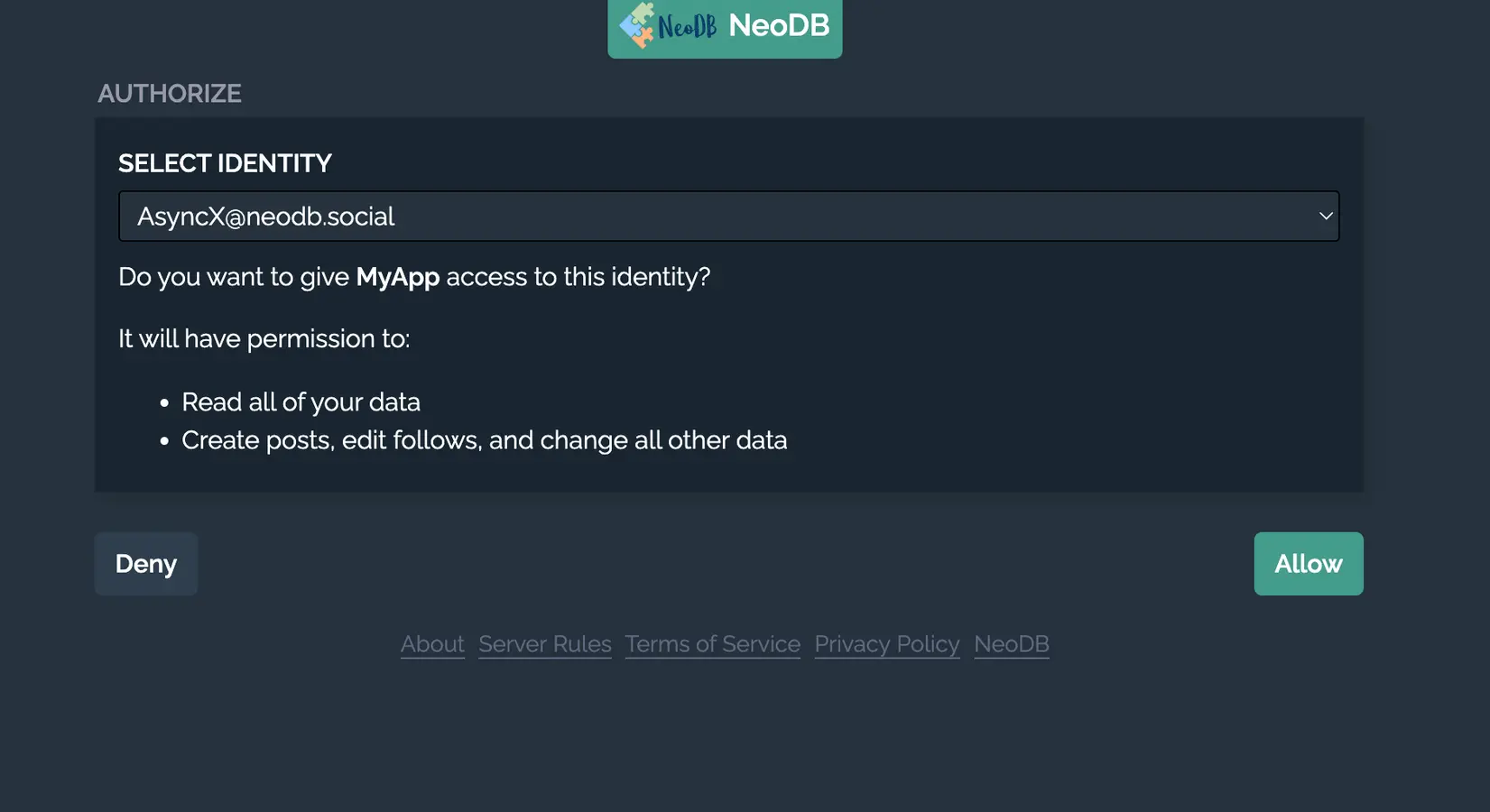
 接着, 你需要在浏览器访问如下的网页链接, 将
接着, 你需要在浏览器访问如下的网页链接, 将[CLIENT_ID]和[REDIRECT_URI]替换成你的输入即可:
https://neodb.social/oauth/authorize?response_type=code&client_id=[CLIENT_ID]&redirect_uri=[REDIRECT_URI]&scope=read+write如果没有问题则会弹出这样的图片, 点击Allow即可, 接着你会跳转你自己的网页, 在浏览器的链接栏你可以看到生成的code.
接着,使用以下指令来生成Token,其中新获得的code也需填写于其中:
curl https://neodb.social/oauth/token \-d "client_id=CLIENT_ID" \-d "client_secret=CLIENT_SECRET" \-d "code=AUTH_CODE" \-d "redirect_uri=https://example.org/callback" \-d "grant_type=authorization_code"生成Token这步, 我会报错
access denied, 但我没有发现任何导致出现错误的问题, 如果有读者发现麻烦留言, 我会同步更新博文. 因此这步后我使用了测试Token. 生成的链接位于https://neodb.social/developer/ 点击Test Access Token即可生成.
在获得并存储了Token后, 接下来进入Github Action的设置中.
2.创建Github存储库和Action
首先创建一个新的GitHub存储库(我创建新库的原因是防止每天定时的更新会让本地的Obsidian频繁拉取更改/让历史记录更清晰), 点击Setting-Security(Secrets and variables)-Action-New repository secret, 将生成的Token填进去, Name为NEODB_ACCESS_TOKEN
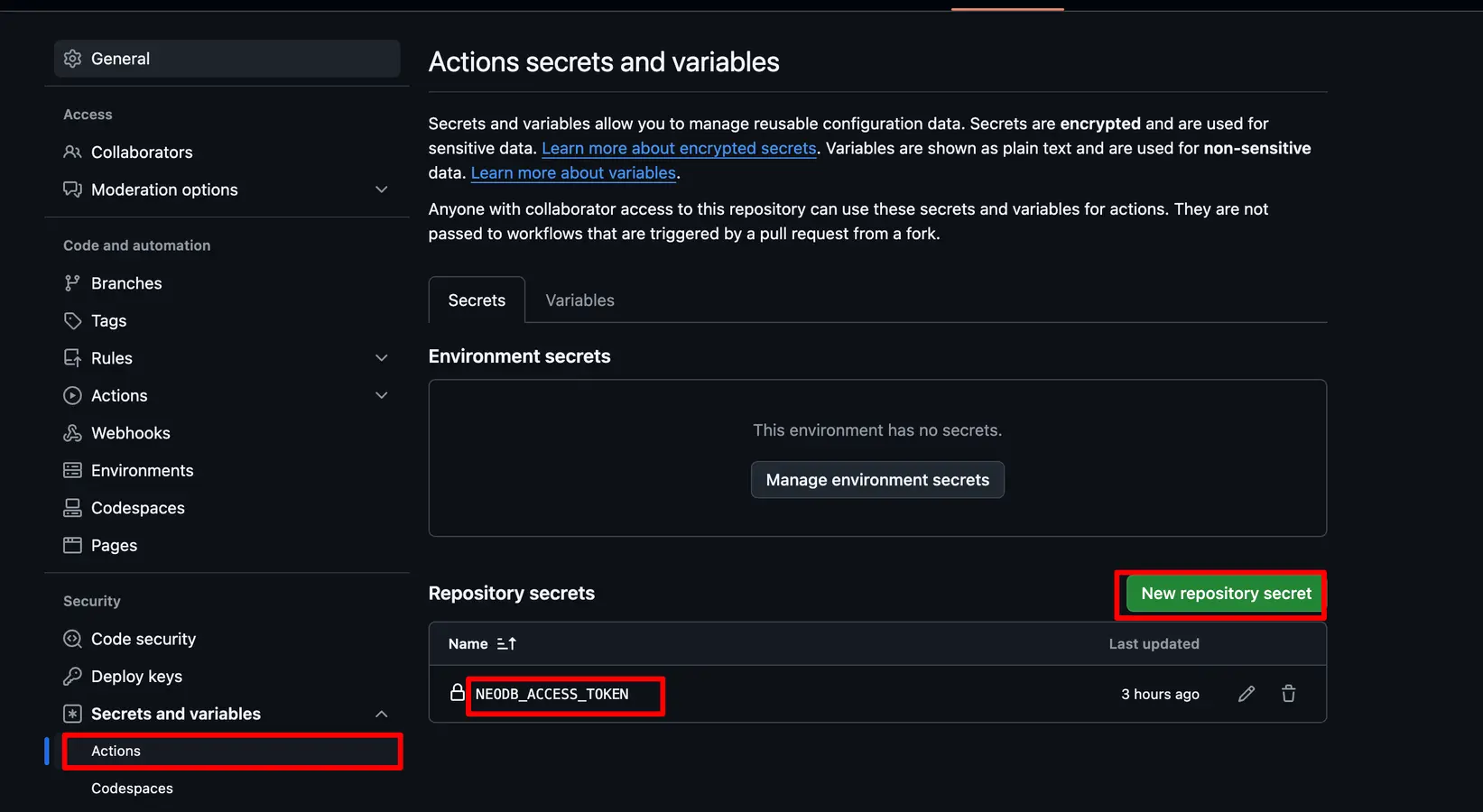 接下来点击
接下来点击Actions-Newworkflow, 复制下面的代码到新建的.yml文件中

name: Sync NeoDB Data
# 允许 GitHub Actions 拥有写入仓库的权限permissions: contents: write
on: schedule: - cron: "0 17 * * *" workflow_dispatch:
jobs: neodb_sync: name: Sync NeoDB Data for multiple categories runs-on: ubuntu-latest
steps: - name: Checkout uses: actions/checkout@v3
- name: Check JQ run: | if ! command -v jq &> /dev/null; then echo "jq is not installed. Installing..." sudo apt-get update sudo apt-get install -y jq else echo "jq is already installed." fi echo "WORK_DIR=$(pwd)" >> $GITHUB_ENV
- name: Ensure local JSON files exist run: | # 定义需要同步的分类(移除 album) categories=("book" "movie" "tv" "game") mkdir -p data/neodb for category in "${categories[@]}"; do local_file="data/neodb/${category}.json" if [ ! -f "$local_file" ]; then echo "Creating default JSON for category: $category" echo '{"data": [], "pages": 0, "count": 0}' > "$local_file" fi done
- name: Sync Categories Data run: | # 定义需要同步的分类(移除 album) categories=("book" "movie" "tv" "game") UPDATED=0
for category in "${categories[@]}"; do echo "Processing category: $category"
# 下载该分类第一页数据,用于获取 count 和 pages curl -s -X GET "https://neodb.social/api/me/shelf/complete?category=${category}&page=1" \ -H "accept: application/json" \ -H "Authorization: Bearer ${{ secrets.NEODB_ACCESS_TOKEN }}" \ -o "${category}1.json"
# 提取远程数据的 count 和 pages, 如果为 null 则设为 0 remote_count=$(jq '.count // 0' "${category}1.json") pages=$(jq '.pages // 0' "${category}1.json") echo "Remote count for ${category}: $remote_count, pages: $pages"
# 读取本地数据的 count local_file="data/neodb/${category}.json" local_count=$(jq '.count // 0' "$local_file") echo "Local count for ${category}: $local_count"
# 对比远程和本地的 count 数值,若一致则跳过下载 if [ "$remote_count" -eq "$local_count" ]; then echo "No update for ${category}. Skipping download." continue else echo "Update detected for ${category}. Downloading all pages..." UPDATED=1 # 为当前分类创建临时目录存储下载数据 mkdir -p "neodb/${category}" if [ "$pages" -gt 0 ]; then # 循环下载所有页数据 for ((i=1; i<=pages; i++)); do echo "Downloading ${category} page $i" curl -s -X GET "https://neodb.social/api/me/shelf/complete?category=${category}&page=$i" \ -H "accept: application/json" \ -H "Authorization: Bearer ${{ secrets.NEODB_ACCESS_TOKEN }}" \ -o "neodb/${category}/${category}${i}.json" done
# 利用 jq 合并所有页面数据为一个 JSON 文件 jq -c -s '{ data: map(.data[]) | unique | sort_by(.created_time) | reverse, pages: (map(.pages)[0]), count: (map(.count)[0]) }' neodb/${category}/*.json > "${category}.json" else # 如果 pages 为 0,则创建默认空数据文件 echo '{"data": [], "pages": 0, "count": 0}' > "${category}.json" fi
# 确保目标目录存在,然后将合并后的 JSON 文件复制过去 mkdir -p data/neodb cp -f "${category}.json" "data/neodb/${category}.json" fi done
# 如果所有分类均未更新,则退出工作流 if [ $UPDATED -eq 0 ]; then echo "No categories updated. Exiting." exit 0 fi
- name: Git Add and Commit uses: EndBug/add-and-commit@v9 with: message: 'chore(data): update neodb data for multiple categories' add: './data/neodb'点击提交, 接下来你需要再次进入Actions并手动Run一下, 不出意外你就可以看到新生成的json文件了.

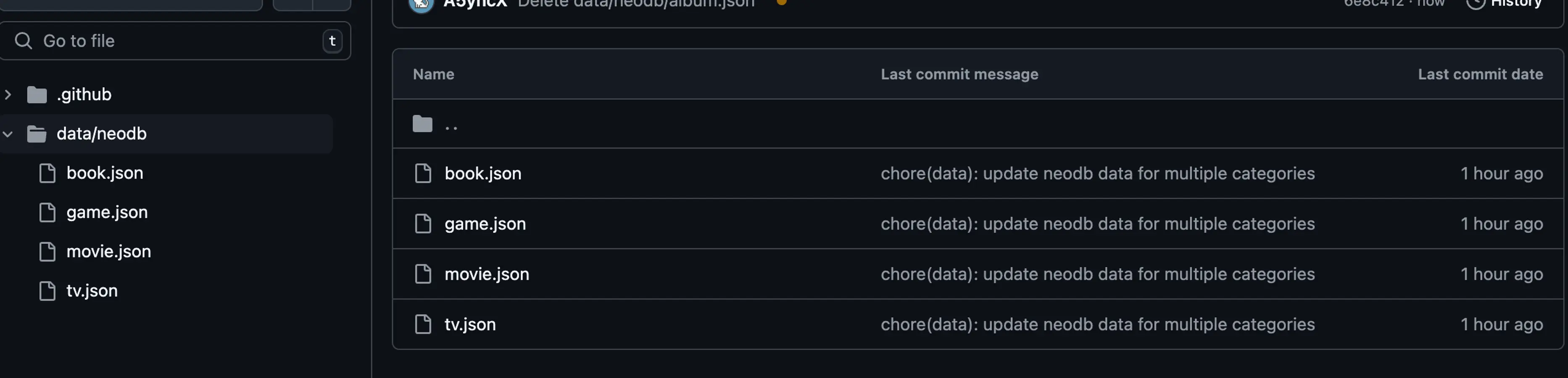 到这一步, 你已经存储了NeoDB的数据, 接下来就是前端工作了.
到这一步, 你已经存储了NeoDB的数据, 接下来就是前端工作了.
3.前端读取和渲染
到了这一步我全权交给了ChatGPT, 由于展示的内容实在很多, 我在尝试了几个想法发现效果不理想后, 最终确定的内容为:
- 展示基于日期的最近3个月内的影音.
- 分类展示基于日期的最新的20个影音.
我在博客的页面目录/pages下创建了新的路径文件/bmmg/index.astro, 这样最终的访问url为https://blog.asyncx.top/bmmg. 对于下面的代码来说, 你需要手动修改一下自定义域名后的json文件url.以及由于我使用了TailwindCSS, 你需要让GPT修改其样式为普通的CSS
---import Layout from "../../layouts/Layout.astro";
// 定义各分类对应的 JSON 文件地址const jsonUrls = { movie: "https://neodb.asyncx.top/data/neodb/movie.json", tv: "https://neodb.asyncx.top/data/neodb/tv.json", game: "https://neodb.asyncx.top/data/neodb/game.json", book: "https://neodb.asyncx.top/data/neodb/book.json"};
// 定义分类中文显示名称const categoryMap = { movie: "影", tv: "剧", game: "游", book: "书"};
// 用于存储各分类的所有数据(不做时间过滤,取最新20条)const grouped = {};
// 用于存储合并后的数据(仅包含过去3个月内的记录)let mergedRecentItems = [];
// 计算当前日期三个月前的日期const now = new Date();const threeMonthsAgo = new Date();threeMonthsAgo.setMonth(now.getMonth() - 3);
// 动态读取各 JSON 文件await Promise.all( Object.entries(jsonUrls).map(async ([cat, url]) => { const res = await fetch(url); const jsonData = await res.json(); // 对该分类所有数据按创建时间降序排序(不做时间过滤) const sortedAll = jsonData.data.sort( (a, b) => new Date(b.created_time) - new Date(a.created_time) ); // 分类展示:取前20条,并附加所属分类信息 grouped[cat] = sortedAll.slice(0, 20).map(item => ({ ...item, category: cat })); // 合并展示:过滤出过去三个月内的记录,并附加所属分类信息 const filteredRecent = jsonData.data.filter( (item) => new Date(item.created_time) >= threeMonthsAgo ).map(item => ({ ...item, category: cat })); mergedRecentItems = mergedRecentItems.concat(filteredRecent); }));
// 对合并后的所有数据按创建时间降序排序,并取前20条mergedRecentItems.sort((a, b) => new Date(b.created_time) - new Date(a.created_time));mergedRecentItems = mergedRecentItems.slice(0, 20);
// 定义生成跳转链接的函数const getLink = (entry) => { if (entry.category === "movie") { // 对于电影,点击跳转到固定的电影 JSON 文件地址 return jsonUrls.movie; } else { // 对于其它分类,构造链接为:https://neodb.social/{分类}/{uuid} return `https://neodb.social/${entry.category}/${entry.item.uuid}`; }};---<Layout title="NeoDB" description="NeoDB"> <div class="container mx-auto py-8"> <h1 class="text-3xl font-bold mb-6">最近看/玩了什么</h1> <!-- <p class="text-gray-500 mb-6"> 上半部分展示过去3个月内的全部记录,下半部分按分类展示各自最新的20条数据。 </p> --> <!-- 全部展示部分:仅展示过去3个月内的记录 --> <section class="mb-8"> <!-- <h2 class="text-2xl font-semibold mb-4">全部</h2> --> {mergedRecentItems && mergedRecentItems.length > 0 ? ( <div class="grid grid-cols-2 md:grid-cols-5 gap-3"> {mergedRecentItems.map((entry) => ( <a href={getLink(entry)} class="block"> <div class="border rounded overflow-hidden shadow hover:shadow-lg transition-shadow"> <img src={entry.item.cover_image_url} alt={entry.item.title} loading="lazy" class="w-full h-48 object-cover" /> </div> <p class="mt-2 text-sm font-bold text-center truncate"> {entry.item.title} </p> </a> ))} </div> ) : ( <p class="text-gray-500">暂无数据</p> )} </section> <hr class="my-8" /> <!-- 分类展示部分:各分类显示最新20条数据,不限制时间 --> {Object.keys(jsonUrls).map((cat) => ( <section class="mb-12"> <h1 class="text-2xl font-semibold mb-4">{categoryMap[cat]}</h1> {grouped[cat] && grouped[cat].length > 0 ? ( <div class="grid grid-cols-2 md:grid-cols-5 gap-3"> {grouped[cat].map((entry) => ( <a href={getLink(entry)} class="block"> <div class="border rounded overflow-hidden shadow hover:shadow-lg transition-shadow"> <img src={entry.item.cover_image_url} alt={entry.item.title} loading="lazy" class="w-full h-48 object-cover" /> </div> <p class="mt-2 text-sm font-bold text-center truncate"> {entry.item.title} </p> </a> ))} </div> ) : ( <p class="text-gray-500">暂无数据</p> )} </section> ))} </div></Layout>4.效果展示/写在最后
将数据存储在本地的好处是不用担心日后哪天失效, 倘若失效还有数据可以展示(笑). 如果我有描述不清晰的地方, 请尽情评论, 我会将没讲清楚的地方更新在文中.